Platform Overview
Following the architecture overview blog, this post goes into detail on our platform and how we build it.
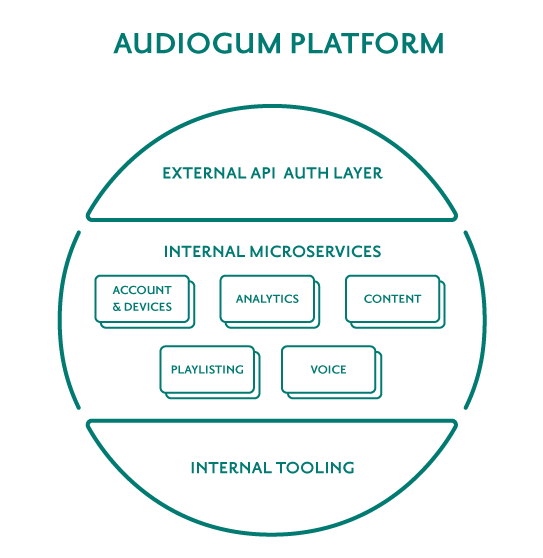
Clojure Microservices
Our platform consists of over forty microservices that we develop using Clojure. Clojure is a dynamic, functional language. It runs on the Java Virtual Machine (JVM) so allows access to the many Java libraries out there. We use Clojure for its speed of development - in short, you write less code and are highly productive. As part of development, we use a Leiningen project template that allows us to create a new functioning RESTful service with monitoring APIs with a single command line. If you’re interested in how we got into Clojure, you might want to watch the talk that Andrew, one of our engineers, gave when we worked together at Nokia back in 2013.
We host our services on Amazon Web Services (AWS) in Europe and Beijing and use Kubernetes to allow us to run many services on each AWS host and maximise efficiency.
Data
We have two large sources of data we deal with - content metadata for millions of songs (along with associated artists, albums, etc.) and analytics data coming in from our clients (such as hardware metrics, playback events and application navigation events).
Our collection of catalogue services provide content metadata and search capabilities that are used by client apps for finding content as well as internally by our playlisting services. We match metadata from various sources and store it in an Amazon Aurora database for offline querying, manual editing and corrections. We then publish summary views of artist and song data to Elasticsearch which our search service is built on.
Collecting analytics and usage data is vital for understanding how products are used, driving personalised experiences, conducting A/B testing, CRM, calculating business metrics and usage reporting. As data arrives in the platform from various clients throughout the day, many of our microservices need access to the same data simultaneously. To handle this volume of data we use a publish-subscribe model (via Amazon Kinesis) to give near real-time access to the events coming in. This allows us to act on the data in parallel - for example, adjusting a playlist or updating a user’s taste profile based on a user action. One of the main subscribers archives the incoming events to file storage, which allows us to make it available for partners through a daily search-index and run Map/Reduce jobs to create summary data to drive the dashboards we provide to partners.
We have used Apache Kafka in the past, but it has a high operational overhead for a small team, so we chose Kinesis for its simpler, managed approach.
Monitoring
We of course commit to a Service Level Agreement with our partners. To fulfill this and drive our on-call alerting, we gather metrics from AWS regions outside of where our core services are hosted and publish our availability and latency on our public status page.
If things go wrong, we need to know about it and react quickly, so we have multiple layers of monitoring in place to alert us. As we’re a small team and like our sleep, we have some automation here to avoid being woken up in the middle of the night! At the lowest level, Kubernetes checks basic health of microservices through their healthcheck APIs and determines if a service needs recycling. We also have a service that checks the health of the AWS hosts that run the containers for our microservices and replaces any unhealthy instances.
We gather metrics from each service using InfuxDB that we query and visualise in Grafana - this lets us create dashboards for various areas of the platform that we want to keep an eye on. Finally, we ship logs to a central Kibana for each environment and then have custom dashboards to track down specific errors or see trends.
Architecture Principles
To keep the service APIs consistent, we have some light standards around URI structures, formats, parameters, casing, dealing with language codes and so on. The service that provides the security layer in front of our microservices extracts various details about the user calling the API and passes them down in a consistent way as headers to the internal services - details like the oem, userid, deviceid, countrycode, and languagecode.
Our services:
- Are loosely coupled and mostly provide a RESTful interface of JSON over HTTP.
- Deploy separately and own their data, i.e. other services access data through APIs, not a datastore connection. This allows separate scale as well as changes in persistence technology and data structure.
- Implement healthcheck APIs for monitoring and are responsible for determining their health.
- Never break their consumers. We have a version number in resource paths (e.g.
/v1/playables/12345/), such that if there is a need for a breaking change, a new version can be deployed side-by-side and get adopted by upstream consumers. - Use Swagger to expose self-documenting APIs.
Along with these internal principles, for our public facing APIs, we add the following:
- APIs are optimised to work on devices with small memory and processing power: we use JSON as parsing has a low memory footprint, responses are encoded with GZIP wherever possible and most importantly - if data is not necessary, it’s not returned. This last point is a fine balance with API consistency.
- Caching is applied wherever possible; APIs return appropriate cache headers such that content gets cached on end-user devices and browsers.
- As much logic and data “truth” as possible is held in the cloud to reduce duplication of logic in apps and give a consistent experience.
- The same API is used for all clients, however, to optimise for different screen sizes and content requirements, we use a few techniques. Firstly, the
itemsperpagequerystring parameter adjusts the amount of content returned. Secondly, we group multiple content results into “views” to reduce the number of requests required.
An example of using a view API would be an artist detail page that consists of data from many resources - artist biography, images, top albums, top songs and similar artists. By combining this into a “view”, apps get the data in one hit of around 5KB.
Summary
You’ve now seen how we make our APIs consistent and the sorts of large data challenges we have and how we tackle them. For more information about our APIs, take a look at our developer docs.
