Audiogum provides APIs for controlling devices through voice commands, either by sending raw audio from a microphone, or text that has been transcribed by a third-party speech-to-text service. The APIs return remote control actions that a device can act upon.

The voice APIs can be used in either streaming mode (via Remote Control WebSocket) or non-streaming mode (REST API).
To activate speech capabilities, a user (typcially through a companion app) must acquire a "delegated" user token via the /v1/tokens API using grant_type=token. The token API will issue a token that can be securely used by a device to operate on the user's behalf that should be passed to the device to securely store and use as it cannot authenticate as the user.
The user must use their own (pre-existing) user authentication access token to create a new token with the scope of speech. For more information about Audiogum authentication, see Authentication
POST /v1/tokens HTTP/1.1
Content-Type: application/json
Authorization: Basic <client_id:secret in base64>
{
"grant_type": "token",
"token": "v1::...",
"scope": "speech",
"deviceid": "<deviceid>"
}
The response contains a body as follows. The access_token, expires_in and refresh_token should be passed to the device.
{
"access_token": "v1::FNJUwKr...",
"refresh_token": "v1::5AspKd...",
"expires_in": 2592000
}
If the user has multiple devices, each device must receive its own dedicated speech token. The deviceid is required in the request.
The access_token passed to the device as above will be used to access either the speech REST or WebSocket API, and the refresh_token should be used to refresh the access token when it expires. See Authentication: Refreshing Tokens.
These tokens are long lived. A speech access token created in this way will last 30 days (or 24 hours for test client_ids), and the refresh token will never expire.
If the device receives a 401 response status (or a voiceerror message with status 401 from the WebSocket) when attempting to access the speech APIs, it should assume the access token has expired. If the speech device fails to refresh the access token, it may retry, but after a small number of retries the device must assume that authorization to use speech services on the user's behalf has been revoked and stop retrying.
To use the streaming API:
nowplaying information.voiceproperties with JSON content that includes nowplaying information whenever the player begins a new track during the voice interaction.The voiceproperties message must be sent by the device on the Remote Control WebSocket to initiate a voice interaction.
It may also be sent again during the interaction as necessary to update nowplaying data if the player state changes.
Each interaction should have a ref generated for it that should be sent in these properties, as well as in voiceevents.
{
"type": "voiceproperties",
"speechtoken": "v1::FNJUwKr...",
"ref": "171d8f27-71c4-44...",
"encoding": "pcm",
"samplerate": 16000,
"languagecode": "en-GB",
"immediate": true,
"reportactivity": true,
"nowplaying": {
"item": {
"name": "A hundred moons",
"artistdisplayname": "GoGo Penguin",
"albumname": "A Humdrum Star",
"duration": 267,
"service": "tidal",
"ref": "84245613",
"id": "0a5d723756f71db06eaeac9cb309c7c9",
"artists": [
{
"id": "26f645b5e354481292533a890c817a4b",
"name": "GoGo Penguin"
}
]
},
"playable": {
"id": "e85d65fe39814a659af67ceb5853efc0",
"userid": "f646b99cdb99455bbd0dfcfe2c5152b4",
"name": "GoGo Penguin",
"startindex": 10,
"parameters": {
"type": "dynamicplaylist",
"service": "tidal",
"variant": "artist"
}
},
"playstate": "playing",
"source": "playable",
"presetnumber": 1,
"offset": 1,
"volume": {
"value": 5,
"mute": false
}
}
}
| Key | Description | Example |
|---|---|---|
type | mandatory | "voiceproperties" |
speechtoken | the access_token supplied to the device, see authorisation, mandatory to begin voice interaction, optional subsequently | |
ref | mandatory reference for voice interaction, app or device should generate a GUID and send in here | "171d8f27-71c4-44ab-a014-421a7c796643" |
samplerate | mandatory to begin interaction, the sample rate of the audio for every sample sent for the duration of the websocket | 16000 |
encoding | mandatory to begin interaction | "pcm" |
languagecode | optional, the language of the voice samples | "en-GB" |
nowplaying | optional, but must be sent if the device is playing. See below. | |
immediate | optional, set to true to enable receiving voicephrase messages | true |
reportactivity | optional, set to true to enable receiving voiceactivity messages | true |
| Key | Description | Example |
|---|---|---|
item | optional, the item that's currently playing. See below. | |
playable | optional, the playable that's currently playing. See below. | |
playstate | optional, the play state of the player. Can be idle, buffering, playing or paused | "idle" |
source | optional, only allowed characters 'a-z', in the case of playing Audiogum playable, shoudl be playable | "playable" |
presetnumber | optional integer, supply if currently playing a preset | 8 |
offset | optional, an integer offset into the currently playing track, in seconds | 0 |
volume | optional, an object describing the playback volume. See below. |
See item analytics documentation
See playable analytics documentation
| Key | Description | Example |
|---|---|---|
value | mandatory, an integer | 11 |
mute | mandatory, a boolean true if and only if the device is muted | false |
To transmit microphone audio for processing, the device must send BINARY messages on the WebSocket. Recommended chunk size is 8KB per message, up to a maximum 32KB per message.
The device should not attempt to send more than 60 seconds of microphone data during the lifetime of a voice interaction. You may receive error messages after this time. Voice interaction can be re-started by sending voiceproperties with the initially required fields.
The Audiogum API will detect voice activity in the incoming audio data. Once voice activity is no longer detected in the incoming bytes (silence, background noise, etc), then the speech will be processed.
If the client does not intend to send trailing audio bytes (silence, background noise, etc), the client must indicate that no more bytes are expected. To do this, the client sends an empty (zero bytes) BINARY message or use the libaudiogum ag_voice_send_mic_terminator function.
When the Audiogum API has completed processing a voice phrase, it will return a TEXT message containing JSON with the type value voiceresult.
The voiceresult may include all the same fields as remotecomand messages from Remote Control API. In particular it may contain actions to be performed by the device and may contain respond indicating a voice response to play to the user.
See the commands documentation for details of actions and related features.
{
"type":"voiceresult",
"text": "play me something",
"actions": [
{
"action": "playplayable",
"parameters": {
"id": "bdfd3200cc6a49938035262cc4b7c5e6"
}
}
],
"respond": {
"languagecode": "en",
"text": "sure, building a mix",
"audio": "http://...08c0483166d78405aae44de9f8f514f24620848274.Amy.mp3"
}
}
If you wish to be notified whenever speech is detected in the incoming audio stream, you can include "reportactivity": true in the voiceproperties message when starting voice interaction. Whenever speech is detected, you will receive a message like:
{
"type": "voiceactivity"
}
This message may be received many times, indicating that voice activity is still being recognised from the audio data. The standard voiceresult message will eventually follow when a phrase is processed.
This mode allows the client to implement smart microphone timeouts. You may wish to keep the microphone open longer whenever you receive a voiceactivity message, and close the microphone only if you have not received voiceactivity for some time.
If you wish to receive an instant reply that describes the transcribed text before Audiogum has processed the phrase, you can include "immediate": true in the voiceproperties message when starting voice interaction. Once a completed phrase has been recognised, you will immediately receive a message like:
{
"type": "voicephrase",
"text": "play me something"
}
This can be used as a signal to close the microphone and stop sending BINARY messages because no more speech will be processed for this interaction.
The standard voiceresult message will follow after the phrase has been processed.
libaudiogum provides various functions that simplify the voice interaction using the Remote Control WebSocket.
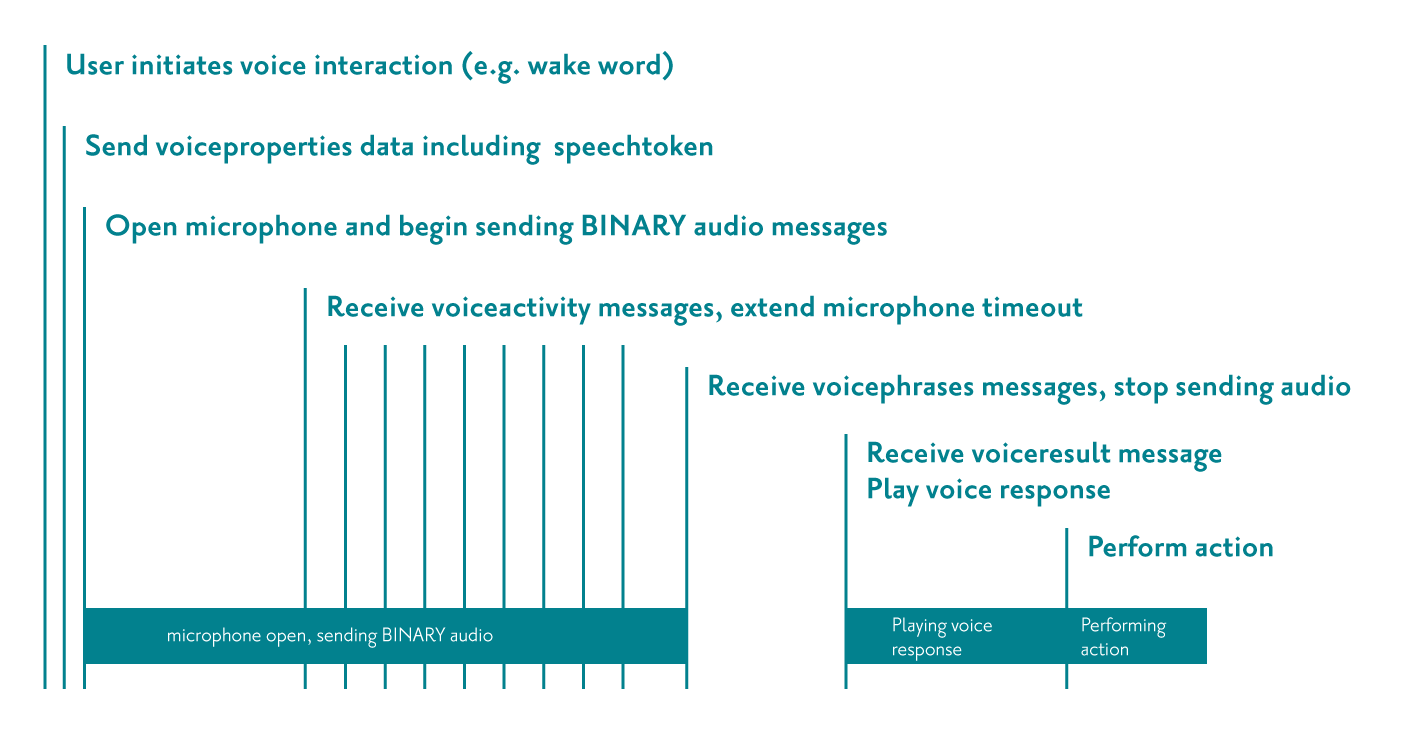
ag_voice_store_delegated_token function.ag_voice_open_session function, that handles initiating the voice interaction.ag_voice_update_now_playing.ag_voice_send_mic_data.ag_action_callback.In the following example, a user initiates voice control on a device and then talks to the device. The user says "play me something", the service interprets and sends the device a voice response and details of the action to play music.
>> TEXT message sent by device to initiate voice interaction
{
"type": "voiceproperties",
"speechtoken": "v1::FNJUwKr...",
"encoding": "pcm",
"samplerate": 16000,
"languagecode": "en-GB",
"immediate": true,
"reportactivity": true,
"nowplaying": {
"playstate": "idle",
"volume": {
"value": 5,
"mute": false
}
}
}
>> BINARY message sent by device (audio data from mic)
>> BINARY message sent by device
>> ...
<< TEXT message received by device to indicate voice activity detected
{
"type": "voiceactivity"
}
>> BINARY message sent by device
>> ...
<< TEXT message received by device to indicate voice activity detected
{
"type": "voiceactivity"
}
>> BINARY message sent by device
>> ...
<< TEXT message received by device to indicate phrase detected, microphone can stop
{
"type": "voicephrase",
"text": "play me something"
}
<< TEXT message received by device with results of processing
{
"type":"voiceresult",
"text": "play me something",
"respond": {
"languagecode": "en",
"text": "sure, building a mix",
"audio": "http://...08c0483166d78405aae44de9f8f514f24620848274.Amy.mp3"
},
"actions": [
{
"action": "playplayable",
"parameters": {
"id": "bdfd3200cc6a49938035262cc4b7c5e6"
}
}
]
}
The following timeline diagram illustrates a typical interaction as above:
If the device sends a TEXT message that cannot be understood by the server (validation error, incorrect structure, unparseable JSON content, etc), the server will send an error TEXT message to the client via the WebSocket, e.g.:
Example:
{
"type": "voiceerror",
"status": 400,
"message": "Received a message that failed validation",
"errors": {"eencoding":"disallowed-key"}
}
If the device receives a message with status 401, it should assume the speech token is expired or invalid. See Authentication: On device. Example:
{
"type": "voiceerror",
"status": 401,
"message": "Speech token expired"
}
If the device attempts to send BINARY messages before voice interaction is properly initated it may receive this message:
{
"type": "voiceerror",
"status": 400,
"message": "Cannot send audio bytes before sending voiceproperties with speechtoken"
}
Voice errors may contain a respond map with text, languagecode and audio as in a voiceresult message. This allows for a explanation of an error to be given as a voice message.
If a device successfully sends audio bytes and we can transcribe the content but can't be understood i.e. the sentence "Blah, blah, blah" it may receive this message:
{
"type": "voiceerror",
"status": 422,
"message": "Detected an utterance, but we did not understand it",
"respond": {
"text" "Sorry, I didn't understand that",
"languagecode": "en",
"audio": "http://...eabd3a77bb33468aaf73fde4973a8f65.Amy.mp3"
},
"text": "Blah, blah, blah"
}
The Remote Control WebSocket may also close in cases of unexpected communication errors, see RFC6455 §7.4.1 for a detailed description of each status code.
If the Remote Control WebSocket closes, any voice interaction ongoing at that time will fail and must be abandoned.
Audiogum can support two-way conversations with devices that indicate that they can use this feature. Conversations are enabled by setting the expectreply capability when connecting the Remote Control WebSocket (see Remote Control: Capabilities).
When enabled, some voiceresult messages may include "expectreply": true. In this case, after processing the respond and actions if any, the device should establish another voice interaction by sending voiceproperties message, opening the microphone and sending binary messages containing the encoded audio.
Whether using the REST API or a websocket, a capabilities parameter should be specified to indicate to the service which features are desired. More details on capabilities can be found on the commands page.
An alternative to the websockets API is the simpler REST API that will work for one-off commands as opposed to continuous listening.
| API | Purpose |
|---|---|
| POST /v1/user/speech | Upload an audio file and receive spoken 'action' |
| POST /v1/user/speech/text | Upload text and receive 'action' |
The POST /v1/user/speech/text API converts the text of an instruction taken from a separate ASR engine into action. The API requires a "delegated" user token - see authorisation. Note that the capabilities parameter passed in controls some feature availability - see the commands page.
POST /v1/user/speech/text HTTP/1.1
Host: api.audiogum.com
Authorization: Bearer …
Content-Type: application/json
{
"capabilities": ["volumeup", "volumedown", "setvolume", "play", "stop"],
"text": "Play some jazz",
"deviceid": "4fac2cc33a05"
}
HTTP/1.1 201 Created
Content-Type: application/json;charset=utf-8
{
"respond": {
"text": "Sure. Fetching you some Jazz",
"languagecode": "en",
"audio": "http://...mp3"
},
"actions": [
{
"action": "playplayable",
"parameters": {
"id": "4b29667aa3024281af83ce009af647d4",
"parameters": {
"service": "tidal",
"tags": [
{
"type": "genre",
"id": "jazz"
}
],
"type": "dynamicplaylist",
"allowunlinkedservice": true,
"variant": "tag"
}
},
"entities": {
"genres": [
{
"id": "jazz",
"name": "Jazz",
}
]
},
"intent": {
"name": "generateplaylist"
}
}
]
}
As shown, the successful case gives a 201 response code, but the Text REST API also returns error codes that match the websocket API:
| Code | Meaning |
|---|---|
| 401 | The speech token is expired or invalid - see Authentication: On device |
| 410 | The phrase given contains a request to generate a dynamic playlist, but Audiogum could not create a playlist to fulfill the requirements (e.g. the requirements are too specific, or we have no relevant music available in the territory) |
| 422 | The phrase given could not be understood, no intent was recognised |
The following examples illustrate some of the features enabled through Audiogum voice integration. Note that this is not an exhaustive list and Audiogum is continuously adding voice control features. New features will be automatically available to existing clients, subject to the capabilities declared by the device.
| intent | example phrases | description |
|---|---|---|
| play | "play" "resume" "continue" "go" | Device plays/resumes |
| stop | "stop" "turn off" | Device stops |
| pause | "pause" "shush" "shut up" | Device pauses |
| skip next | "skip" "skip this" "next" "skip forward" "next song" | Device skips to the next track |
| skip previous | "skip previous" "go back" "previous" "previous song" | Device skips to the previous track |
| volume up | "louder" "volume up" "increase volume" "turn it up" | Device increases volume |
| volume down | "quieter" "volume down" "decrease volume" "turn it down" | Device decreases volume |
| volume quiet | "hush" "quiet" "make it quiet" | Device sets volume to specified value. |
| volume loud | "loud" "play loud" "make it loud" | Device increases volume by specified relative value. |
| shuffle | "shuffle" "random" "unshuffle" "turn off random" | Indicates that the client should activate or deactivate 'shuffle' mode |
| repeat | "repeat" "repeat this song" "stop repeating" | Indicates that the client should activate or deactivate 'repeat' mode |
The following examples illustrate some of the informational features enabled through Audiogum voice integration. As above, this is not an exhaustive list and Audiogum is continuously adding voice control features. New features will be automatically available to existing clients, subject to the capabilities declared by the device and potential licensing costs with 3rd party providers.
These informational responses use the nowplaying information sent by the device alongside the voice request. For the artist and album informational intents, specific named items can also be used.
| intent | example phrases | description |
|---|---|---|
| get now playing info | "what's this?" "what is playing?" "what song is this?" "who is this?" "what artist is this?" | Returns voice response with info about current playing content. E.g. "This is Wonderwall by Oasis". |
| get artist info | "tell me about this artist" "can you tell me about this band" "tell me about Katy Perry" | Returns voice response with info about the current playing artist or a specific artist. E.g. "Katheryn Elizabeth Hudson, known professionally as Katy Perry, is an American singer, songwriter, actress, and television personality." |
| get artist timespan | "when did this artist start?" "when did this band break up?" "when did David Bowie die?" | Returns voice response with info about when the current playing artist or a specific artist started, broke up or died. E.g. "David Bowie died on 10th January 2016". |
| get performance info | "who performs on this?" "who played bass?" "who sung backing vocals?" | Where available, returns voice response with info about who performed the specified role(s) on the song in the now playing data reported by the device. E.g. "Bass was performed by Billy Gould". |
| get album info | "tell me about this album" "tell me about the album Simulation Theory by Muse" | Returns voice response with info about the current album or a specific album. E.g. "Simulation Theory is the eighth studio album by English rock band Muse. It was released on 9 November 2018 through Warner Bros. Records and Helium-3." |
| get concert info | "when are this band playing near me?" | Where available, returns voice response with info about upcoming concerts for the current playing artist or a specific artist. E.g. "Elton John is playing at Royal Arena in Copenhagan on May 18th 2019". |
| get chart info | "what was number one on 3rd May 2016?" "what was number 1 this time last year?" | Where available, returns voice response with info about the chart. E.g. "One Dance by Drake featuring Wizkid and Kyla was number one on 3rd May 2016". |
| help | "what can I say?" "help" | Returns voice response with example phrases to try, based on the user's taste profile if available, or popular artists for the country if not. E.g. "I understand artists and genres. What about asking me to Play David Bowie." |
The following examples illustrate some of the dynamic playlisting and other forms of playback enabled through Audiogum voice integration. Again, this is not an exhaustive list and Audiogum is continuously adding voice control features. New features will be automatically available to existing clients, subject to the capabilities declared by the device and potential licensing costs with 3rd party providers.
| intent | example phrases | description |
|---|---|---|
| create dynamic playlist | "play me something" "play something I'll like" "play something else" "please play 90s music" "play a mix" "play some fast music" "make a slow playlist" "play me Oasis" "play me the top ten from 1st September 1997" "play music from Bristol" "Play popular music" | Service generates a dynamic playlist with parameters based on recognised entities such as artists and genres, if any, or alternatively a personalised playlist based on the user's taste Response includes the playable to play and a voice response e.g "OK, let me find something you'll like" or "Playing some Rock from the 80s" Device starts playback of the specified playable after playing the response. Supported entities include genres, artists, eras, years, tempo (fast, slow), locations, dates (for charts) and more |
| stick to current [artist, genre, era] | "stick to this artist" "only this genre" "keep with this genre" "stick with this era" "more Foo Fighters" "stick to Celine Dion" "keep to Charlotte Gainsbourg" | Service adjusts or creates a new dynamic playlist based on what is currently playing and what is asked for. Response includes new playable id and voice response e.g. "OK, let's stick with Oasis" Device replaces its cache of subsequent songs with those from the specified playable without interrupting the current song, so that the next track is from the new or updated playable. (Note refreshplayable action means the device should not interrupt the current song) |
| modify playlist | "make it faster" | As above but the change is immediate. Response includes the new playable and voice response e.g. "OK, speeding it up" Device starts playback of the specified playable and plays the audio response simultaneously. |
| play playlist | "play 70s Punk Classics" | Play a specific playlist from a music service. |
| play radio | "play BBC Radio 6 Music" | Play a specific internet radio station. |
| play album | "play Nevermind" "play OK Computer by Radiohead" "Play the new album by Rihanna" | Play a specific album. |
| play song | "play Hey Jude" "play Teardrop by Massive Attack" | Generate and play a dynamic playlist starting with a specific recognised song. |
| play song by lyric | "play the song that goes on a dark desert highway" | Generate and play a dynamic playlist starting with a song found by lyric search. |
| like | "I love this" "I like this" | Adds taste information to the user's profile based on what is currently playing |
| dislike | "I hate this" "I don't like this" | Adds taste information to the user's profile based on what is currently playing and where possible generates and plays something else |
| play playlist | "play my driving playlist" | Plays a specified playlist from the user's linked music service |
| set preset | "set this as preset 2" | Stores whatever is currently playing as a preset |
| play preset | "preset three" "switch to first preset" "start preset channel two" "play favourite 3" | Device plays the specified preset channel |